About
Autovar can be used to find VAR models for time series data. Its main functionality is producing a list of VAR models that do not invalidate the model assumptions. Autovar can summarize over the models to provide insight into, e.g., significant contemporaneous correlation and Granger causalities present in the data set.
While Autovar is available as an R package, part of its functionality is exposed through this web application, running some of the exported Autovar functions (depending on the options selected) and showing the results.
Example data sets and use
To reproduce the results from one of the data sets used in our IEEE JBHI paper, please download the Dataset45Jdaggem.dta data set file.
Load the file in Autovar by clicking "Browse" or "Choose file" above. The user interface will then change as it reads the columns from the data set. Set it to select the "Stre" and "Musc" columns as shown below.
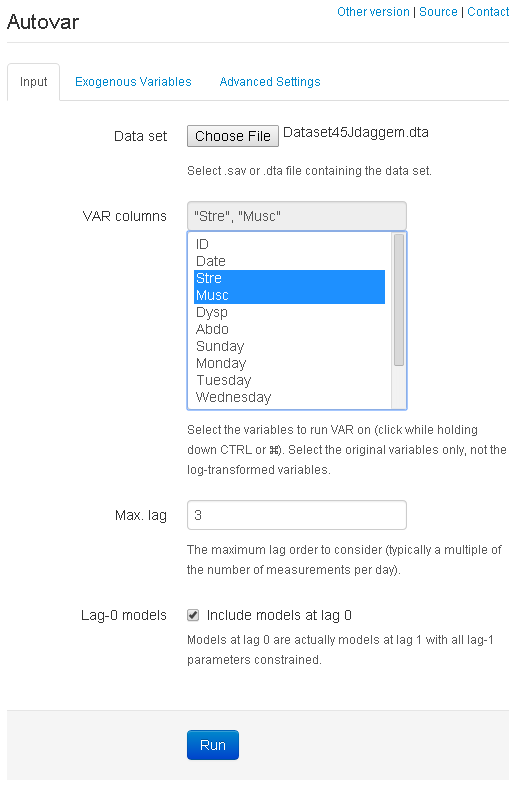
Here, we opt to include lag 0 models as well by ticking the box.
Optionally, we can provide Autovar with some more information about the data set. For example, if we know that this data set describes a study with a single measurement per day, and the first measurement was completed on the 3rd of March, we can specify this as shown in the image below. Setting timestamps enables Autovar to generate and possibly include dummy variables for days and day parts in its models, to account for cyclity if needed.
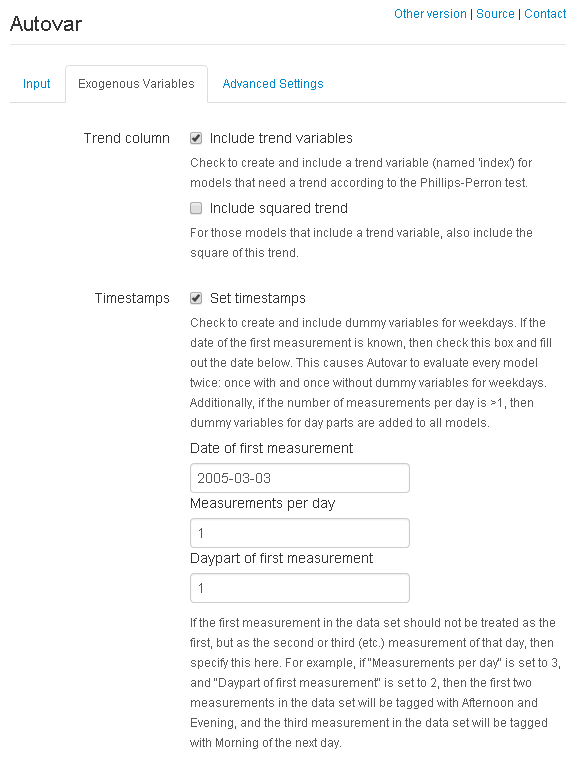
Finally, check "Sort output using BIC instead of AIC" for "Model evaluation" on the "Advanced Settings" tab (not shown). Pressing "Run" will then show the output of running a sequence of functions(*) exported by the Autovar package. If all went correctly, the tab on the right should show as part of its output the following:
The valid models (sorted by BIC score):
A: (AIC: 1253.375 (orig: 277.265), BIC: 1274.814 (orig: 298.704)) : Musc ~Granger causes~ Stre (0.00332); Stre -Granger causes- Musc (0.000955)
followed by the model details. Note that the listed 1274.814 BIC score corresponds to the number displayed in the row for "45 Stre Musc" in Table I of our IEEE JBHI paper as the BIC score of the best model found by Autovar.
- Another data set is presented in aug_pp5_da.sav. This data set works with all settings at default. Simply click "Choose file" to select the data set, select "Activity" and "Depression" as VAR columns, and press "Run."
- Also available is the data set Dataset57Sdaggem.dta. For this data set, use the same settings as for Dataset47Jdaggem.dta described above, but for the Stre Bowe combination, specify max. lag 7 on the input tab and check "Exclude more outliers" on the advanced settings tab.
(*) To reproduce these results using the R package rather than this web app, note that for the given settings, Autovar loads the data set using load_file, adds a trend column using add_trend, adds day dummy columns using set_timestamps, plots the variables using visualize (not required), and then looks for var models and summarize over then by calling var_main, contemporaneous_correlations_plot, var_summary, and print_best_models. The source code for all these functions is publicly available on GitHub. For syntax help on all exported functions, please see the docs section.